This is the 100 days of Machine Learning, Deep Learning, AI, and Optimization mini-projects that I picked up at the start of January 2022. I have used various environments and Google Colab for this work as it required various libraries and datasets to be downloaded. The following are the problems that I tackled:
- Day 1 (01/01/2022): GradCAM Implementation on Dogs v/s Cats using VGG16 pretrained models
| Classification for Cat (GradCAM-based Explainability) | Classification for Dog (GradCAM-based Explainability) |
|---|---|
 |
 |
- Day 2 (01/02/2022): Multi-task Learning (focussed on Object Localization)

- Day 3 (01/03/2022): Implementing GradCAM on Computer Vision problems
- GradCAM for Semantic Segmentation
- GradCAM for ObjectDetection
| Computer Vision domains | CAM methods used | Detected Images | CAM-based images |
|---|---|---|---|
| Semantic Segmentation | GradCAM |  |
 |
| Object Detection | EigenCAM |  |
 |
| Object Detection | AblationCAM | |
 |
- Day 4 (01/04/2022): Deep Learning using PointNet-based Dataset
- Classification
| 3D Point Clouds | Meshes Used | Sampled Meshes |
|---|---|---|
| Beds |  |
 |
| Chair | TBA |  |
- Segmentation

- Day 5 (01/05/2022): Graph Neural Network on YouChoose dataset
- Implementing GNNs on YouChoose-Click dataset
- Implementing GNNs on YouChoose-Buy dataset
| Dataset | Loss Curve | Accuracy Curve |
|---|---|---|
| YouChoose-Click |  |
 |
| YouChoose-Buy |  |
 |
- Day 6 (01/06/2022): Graph neural Network for Recommnedation Systems
- Day 7 (01/07/2022): Vision Transformers for efficient Image Classification
| SN | Training and Validation Metrices |
|---|---|
| 1 |  |
| 2 |  |
- Day 8 (01/08/2022): Graph Neural Networks for Molecular Machine Learning
| Loss Metrices |
|---|
 |
-
Day 9 (01/09/2022): Latent 3D Point Cloud Generation using GANs and Auto Encoders
-
Day 10 (01/10/2022): Deep Learning introduced on Audio Signal
-
Day 11 (01/11/2022): Ant-Colony Optimization
Explore Difference between Ant Colony Optimization and Genetic Algorithms for Travelling Salesman Problem.
| Methods Used | Geo-locaion graph |
|---|---|
| Ant Colony Optimization |  |
| Genetic Algorithm |  |
-
Day 12 (01/12/2022): Particle Swarm Optimization
-
Day 13 (01/13/2022): Cuckoo Search Optimization
-
Day 14 (01/14/2022): Physics-based Optimization algorithms Explored the contents of Physics-based optimization techniques such as:
- Tug-Of-War Optimization (Kaveh, A., & Zolghadr, A. (2016). A novel meta-heuristic algorithm: tug of war optimization. Iran University of Science & Technology, 6(4), 469-492.)
- Nuclear Reaction Optimization (Wei, Z., Huang, C., Wang, X., Han, T., & Li, Y. (2019). Nuclear Reaction Optimization: A novel and powerful physics-based algorithm for global optimization. IEEE Access.)
+ So many equations and loops - take time to run on larger dimension
+ General O (g * n * d)
+ Good convergence curse because the used of gaussian-distribution and levy-flight trajectory
+ Use the variant of Differential Evolution
- Henry Gas Solubility Optimization (Hashim, F. A., Houssein, E. H., Mabrouk, M. S., Al-Atabany, W., & Mirjalili, S. (2019). Henry gas solubility optimization: A novel physics-based algorithm. Future Generation Computer Systems, 101, 646-667.)
+ Too much constants and variables
+ Still have some unclear point in Eq. 9 and Algorithm. 1
+ Can improve this algorithm by opposition-based and levy-flight
+ A wrong logic code in line 91 "j = id % self.n_elements" => to "j = id % self.n_clusters" can make algorithm converge faster. I don't know why?
+ Good results come from CEC 2014
- Day 15 (01/15/2022): Human Activity-based Optimization algorithms Explored the contents of Human Activity-based optimization techniques such as:
- Queuing Search Algorithm (Zhang, J., Xiao, M., Gao, L., & Pan, Q. (2018). Queuing search algorithm: A novel metaheuristic algorithm for solving engineering optimization problems. Applied Mathematical Modelling, 63, 464-490.)
-
Day 16 (01/16/2022): Evolutionary Optimization algorithms Explored the contents of Human Activity-based optimization techniques such as: Genetic Algorithms (Holland, J. H. (1992). Genetic algorithms. Scientific american, 267(1), 66-73) Differential Evolution (Storn, R., & Price, K. (1997). Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. Journal of global optimization, 11(4), 341-359) Coral Reefs Optimization Algorithm (Salcedo-Sanz, S., Del Ser, J., Landa-Torres, I., Gil-López, S., & Portilla-Figueras, J. A. (2014). The coral reefs optimization algorithm: a novel metaheuristic for efficiently solving optimization problems. The Scientific World Journal, 2014)
-
Day 17 (01/17/2022): Swarm-based Optimization algorithms Explored the contents of Swarm-based optimization techniques such as:
- Particle Swarm Optimization (Eberhart, R., & Kennedy, J. (1995, October). A new optimizer using particle swarm theory. In MHS'95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science (pp. 39-43). IEEE)
- Cat Swarm Optimization (Chu, S. C., Tsai, P. W., & Pan, J. S. (2006, August). Cat swarm optimization. In Pacific Rim international conference on artificial intelligence (pp. 854-858). Springer, Berlin, Heidelberg)
- Whale Optimization (Mirjalili, S., & Lewis, A. (2016). The whale optimization algorithm. Advances in engineering software, 95, 51-67)
- Bacterial Foraging Optimization (Passino, K. M. (2002). Biomimicry of bacterial foraging for distributed optimization and control. IEEE control systems magazine, 22(3), 52-67)
- Adaptive Bacterial Foraging Optimization (Yan, X., Zhu, Y., Zhang, H., Chen, H., & Niu, B. (2012). An adaptive bacterial foraging optimization algorithm with lifecycle and social learning. Discrete Dynamics in Nature and Society, 2012)
- Artificial Bee Colony (Karaboga, D., & Basturk, B. (2007, June). Artificial bee colony (ABC) optimization algorithm for solving constrained optimization problems. In International fuzzy systems association world congress (pp. 789-798). Springer, Berlin, Heidelberg)
- Pathfinder Algorithm (Yapici, H., & Cetinkaya, N. (2019). A new meta-heuristic optimizer: Pathfinder algorithm. Applied Soft Computing, 78, 545-568)
- Harris Hawks Optimization (Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., & Chen, H. (2019). Harris hawks optimization: Algorithm and applications. Future Generation Computer Systems, 97, 849-872)
- Sailfish Optimizer (Shadravan, S., Naji, H. R., & Bardsiri, V. K. (2019). The Sailfish Optimizer: A novel nature-inspired metaheuristic algorithm for solving constrained engineering optimization problems. Engineering Applications of Artificial Intelligence, 80, 20-34)
Credits (from Day 14--17): Learnt a lot due to Nguyen Van Thieu and his repository that deals with metaheuristic algorithms. Plan to use these algorithms in the problems enountered later onwards.
-
Day 18 (01/18/2022): Grey Wolf Optimization Algorithm
-
Day 19 (01/19/2022): Firefly Optimization Algorithm
-
Day 20 (01/20/2022): Covariance Matrix Adaptation Evolution Strategy Referenced from CMA (can be installed using
pip install cma)
| CMAES without bounds | CMAES with bounds |
|---|---|
 |
 |
Refered from: Nikolaus Hansen, Dirk Arnold, Anne Auger. Evolution Strategies. Janusz Kacprzyk; Witold Pedrycz. Handbook of Computational Intelligence, Springer, 2015, 978-3-622-43504-5. ffhal-01155533f
- Day 21 (01/21/2022): Copy Move Forgery Detection using SIFT Features
| S. No | Forged Images | Forgery Detection in Images |
|---|---|---|
| 1 |  |
 |
| 2 |  |
 |
| 3 |  |
 |
- Day 22 (01/22/2022): Contour Detection using OpenCV
| Contour Approximation Method | Retrieval Method | Actual Image | Contours Detected |
|---|---|---|---|
| CHAIN_APPROX_NONE | RETR_TREE |  |
 |
| CHAIN_APPROX_SIMPLE | RETR_TREE | |
 |
| CHAIN_APPROX_SIMPLE | RETR_CCOMP |  |
 |
| CHAIN_APPROX_SIMPLE | RETR_LIST | |
 |
| CHAIN_APPROX_SIMPLE | RETR_EXTERNAL | |
 |
| CHAIN_APPROX_SIMPLE | RETR_TREE | |
 |
Referenced from here
- Day 23 (01/23/2022): Simple Background Detection using OpenCV
| File used | Actual File | Estimated Background |
|---|---|---|
| Video 1 |  |
 |
-
Day 24 (01/24/2022): Basics of Quantum Machine Learning with TensorFlow-Quantum Part 1
-
Day 25 (01/25/2022): Basics of Quantum Machine Learning with TensorFlow-Quantum Part 2
-
Day 26 (01/26/2022): Latent Space Representation Part 1: AutoEncoders
| Methods used | t-SNE Representation |
|---|---|
| Using PCA |  |
| Using Autoencoders |  |
- Day 27 (01/27/2022): Latent Space Representation Part 2: Variational AutoEncoders
| Methods used | Representation |
|---|---|
| Using PCA | |
| Using Variational Autoencoders |  |
- Day 28 (01/28/2022): Latent Space Representation Part 3: Deep Convolutional Generative Adversarial Networks
| Methods used | Representation |
|---|---|
| Using Generative Adversarial Networks |  |
-
Day 29 (01/29/2022): Entity Recognition in Natural Language Processing
-
Day 30 (01/30/2022): Head-Pose Detection using 3D coordinates for Multiple People
| Library Used | Actual Image | Facial Detection | Facial Landmarks | Head Pose Estimation |
|---|---|---|---|---|
| Haar Cascades |  |
 |
(To be done) | (To be done) |
| Haar Cascades |  |
 |
(To be done) | (To be done) |
| Mult-task Cascaded Convolutional Neural Networks | |
 |
 |
 |
| Mult-task Cascaded Convolutional Neural Networks | |
 |
 |
 |
| OpenCV's Deep Neural Network | |
 |
 |
 |
| OpenCV's Deep Neural Network | |
 |
 |
 |
(Yet to use Dlib for facial detection.)
- Day 31 (01/31/2022): Depth Estimation for face using OpenCV
| Model Used | Actual Image | Monocular Depth Estimation | Depth Map |
|---|---|---|---|
| MiDaS model for Depth Estimation |  |
 |
 |
| MiDaS model for Depth Estimation |  |
 |
 |
Ref: (The model used was Large Model ONNX file)
- Day 32 - 37 (02/01/2022 - 02/06/2022): [Exploring Latent Spaces in Depth]
| Model Used | Paper Link | Pictures |
|---|---|---|
| Auxiliary Classifier GAN | Paper |  |
| Bicycle GAN | Paper |  |
| Conditional GAN | Paper | |
| Cluster GAN | Paper |  |
| Context Conditional GAN | Paper |  |
| Context Encoder | Paper |  |
| Cycle GAN | Paper |  |
| Deep Convolutional GAN | Paper |  |
| DiscoGANs | Paper |  |
| Enhanced SuperRes GAN | Paper |  |
| InfoGAN | Paper |  |
| MUNIT | Paper |  |
| Pix2Pix | Paper |  |
| PixelDA | Paper | |
| StarGAN | Paper |  |
| SuperRes GAN | Paper |  |
| WGAN DIV | Paper |  |
| WGAN GP | Paper |  |
-
Day 38 (02/07/2022): Human Activity Recognition, Non-Maximum Supression, Object Detection
-
Day 39 (02/08/2022): Pose Estimation using different Algorithms
-
Day 40 (02/09/2022): Optical Flow Estimation
-
Day 41 (02/10/2022): Vision Transformers Explainability
-
Day 42 (02/11/2022): Explainability in Self Driving Cars
-
Day 43 (02/12/2022): TimeSformer Intuition
-
Day 44 (02/13/2022): Image Deraining Implementation using SPANet Referred from: RESCAN by Xia Li et al. The CUDA extension references pyinn by Sergey Zagoruyko and DSC(CF-Caffe) by Xiaowei Hu!!
-
Day 45 (02/14/2022): G-SimCLR Intuition
-
Day 46 (02/15/2022): Topic Modelling in Natural Language Processing
-
Day 47 (02/16/2022): img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation This repository draws directly from the one mentioned here. I've tried implementing it on different datasets such as the BIWI ad AWFL dataset. Furthermore, the models weren't trained from scratch. The run was meant to be a way to report the numbers in the paper.
Paper accepted to the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021

Summary: This repository provides a novel method for six degrees of fredoom (6DoF) detection on multiple faces without the need of prior face detection. After prediction, one can visualize the detections (as show in the figure above), customize projected bounding boxes, or crop and align each face for further processing. See details below.
Paper details
Vítor Albiero, Xingyu Chen, Xi Yin, Guan Pang, Tal Hassner, "img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation," CVPR, 2021, arXiv:2012.07791
Abstract
We propose real-time, six degrees of freedom (6DoF), 3D face pose estimation without face detection or landmark localization. We observe that estimating the 6DoF rigid transformation of a face is a simpler problem than facial landmark detection, often used for 3D face alignment. In addition, 6DoF offers more information than face bounding box labels. We leverage these observations to make multiple contributions: (a) We describe an easily trained, efficient, Faster R-CNN--based model which regresses 6DoF pose for all faces in the photo, without preliminary face detection. (b) We explain how pose is converted and kept consistent between the input photo and arbitrary crops created while training and evaluating our model. (c) Finally, we show how face poses can replace detection bounding box training labels. Tests on AFLW2000-3D and BIWI show that our method runs at real-time and outperforms state of the art (SotA) face pose estimators. Remarkably, our method also surpasses SotA models of comparable complexity on the WIDER FACE detection benchmark, despite not been optimized on bounding box labels.
Video Spotlight CVPR 2021 Spotlight
Installation
Install dependecies with Python 3.
pip install -r requirements.txt
Install the renderer, which is used to visualize predictions. The renderer implementation is forked from here.
cd Sim3DR
sh build_sim3dr.sh
Training Prepare WIDER FACE dataset First, download our annotations as instructed in Annotations.
Download WIDER FACE dataset and extract to datasets/WIDER_Face.
Then, to create the train and validation files (LMDB), run the following scripts.
python3 convert_json_list_to_lmdb.py \
--json_list ./annotations/WIDER_train_annotations.txt \
--dataset_path ./datasets/WIDER_Face/WIDER_train/images/ \
--dest ./datasets/lmdb/ \
-—train
This first script will generate a LMDB dataset, which contains the training images along with annotations. It will also output a pose mean and std deviation files, which will be used for training and testing.
python3 convert_json_list_to_lmdb.py \
--json_list ./annotations/WIDER_val_annotations.txt \
--dataset_path ./datasets/WIDER_Face/WIDER_val/images/ \
--dest ./datasets/lmdb
This second script will create a LMDB containing the validation images along with annotations.
Train Once the LMDB train/val files are created, to start training simple run the script below.
CUDA_VISIBLE_DEVICES=0 python3 train.py \
--pose_mean ./datasets/lmdb/WIDER_train_annotations_pose_mean.npy \
--pose_stddev ./datasets/lmdb/WIDER_train_annotations_pose_stddev.npy \
--workspace ./workspace/ \
--train_source ./datasets/lmdb/WIDER_train_annotations.lmdb \
--val_source ./datasets/lmdb/WIDER_val_annotations.lmdb \
--prefix trial_1 \
--batch_size 2 \
--lr_plateau \
--early_stop \
--random_flip \
--random_crop \
--max_size 1400
To train with multiple GPUs (in the example below 4 GPUs), use the script below.
python3 -m torch.distributed.launch --nproc_per_node=4 --use_env train.py \
--pose_mean ./datasets/lmdb/WIDER_train_annotations_pose_mean.npy \
--pose_stddev ./datasets/lmdb/WIDER_train_annotations_pose_stddev.npy \
--workspace ./workspace/ \
--train_source ./datasets/lmdb/WIDER_train_annotations.lmdb \
--val_source ./datasets/lmdb/WIDER_val_annotations.lmdb \
--prefix trial_1 \
--batch_size 2 \
--lr_plateau \
--early_stop \
--random_flip \
--random_crop \
--max_size 1400 \
--distributed
Training on your own dataset If your dataset has facial landmarks and bounding boxes already annotated, store them into JSON files following the same format as in the WIDER FACE annotations.
If not, run the script below to annotate your dataset. You will need a detector and import it inside the script.
python3 utils/annotate_dataset.py
--image_list list_of_images.txt
--output_path ./annotations/dataset_name
After the dataset is annotated, create a list pointing to the JSON files there were saved. Then, follow the steps in Prepare WIDER FACE dataset replacing the WIDER annotations with your own dataset annotations. Once the LMDB and pose files are created, follow the steps in Train replacing the WIDER LMDB and pose files with your dataset own files.
Testing To evaluate with the pretrained model, download the model from Model Zoo, and extract it to the main folder. It will create a folder called models, which contains the model weights and the pose mean and std dev that was used for training.
If evaluating with own trained model, change the pose mean and standard deviation to the ones trained with.
Visualizing trained model To visualize a trained model on the WIDER FACE validation set run the notebook visualize_trained_model_predictions.
WIDER FACE dataset evaluation If you haven't done already, download the WIDER FACE dataset and extract to datasets/WIDER_Face.
Download the pre-trained model.
python3 evaluation/evaluate_wider.py \
--dataset_path datasets/WIDER_Face/WIDER_val/images/ \
--dataset_list datasets/WIDER_Face/wider_face_split/wider_face_val_bbx_gt.txt \
--pose_mean models/WIDER_train_pose_mean_v1.npy \
--pose_stddev models/WIDER_train_pose_stddev_v1.npy \
--pretrained_path models/img2pose_v1.pth \
--output_path results/WIDER_FACE/Val/
To check mAP and plot curves, download the eval tools and point to results/WIDER_FACE/Val.
AFLW2000-3D dataset evaluation Download the AFLW2000-3D dataset and unzip to datasets/AFLW2000.
Download the fine-tuned model.
Run the notebook aflw_2000_3d_evaluation.
BIWI dataset evaluation Download the BIWI dataset and unzip to datasets/BIWI.
Download the fine-tuned model.
Run the notebook biwi_evaluation.
Testing on your own images
Run the notebook test_own_images.
Output customization
For every face detected, the model outputs by default:
- Pose: rx, ry, rz, tx, ty, tz
- Projected bounding boxes: left, top, right, bottom
- Face scores: 0 to 1
Since the projected bounding box without expansion ends at the start of the forehead, we provide a way of expanding the forehead invidually, along with default x and y expansion.
To customize the size of the projected bounding boxes, when creating the model change any of the bounding box expansion variables as shown below (a complete example can be seen at visualize_trained_model_predictions).
# how much to expand in width
bbox_x_factor = 1.1
# how much to expand in height
bbox_y_factor = 1.1
# how much to expand in the forehead
expand_forehead = 0.3
img2pose_model = img2poseModel(
...,
bbox_x_factor=bbox_x_factor,
bbox_y_factor=bbox_y_factor,
expand_forehead=expand_forehead,
)Align faces To detect and align faces, simply run the command below, passing the path to the images you want to detect and align and the path to save them.
python3 run_face_alignment.py \
--pose_mean models/WIDER_train_pose_mean_v1.npy \
--pose_stddev models/WIDER_train_pose_stddev_v1.npy \
--pretrained_path models/img2pose_v1.pth \
--images_path image_path_or_list \
--output_path path_to_save_aligned_faces
Resources
Referred from here directly.
-
Day 48 (02/17/2022): Geometric Deep Learning Tutorials Part I This folder contains the tutorials that I watched and implemented on Day 48th of 100 days of AI. I also referred to some of the papers, medium articles, and distill hub articles to improve my basics of Geometric Deep Learning.
-
Day 49 (02/18/2022): Geometric Deep Learning Tutorials Part II This was the follow-up for the Geometric Deep Learning that I did on Day 48th. Today I read few research papers from ICML for Geometric Deep Learning and Graph Representation Learning.
-
Day 50 (02/19/2022): Topic Modelling using LSI
-
Day 51 (02/20/2022): Semantic Segmentation using Multimodal Learning Intuition
Segmentation of differenct components of a scene using deep learning & Computer Vision. Making uses of multiple modalities of a same scene ( eg: RGB image, Depth Image, NIR etc) gave better results compared to individual modalities.
We used Keras for implementation of Fully convolutional Network (FCN-32s) trained to predict semantically segmented images of forest like images with rgb & nir_color input images. (check out the presentation @ https://docs.google.com/presentation/d/1z8-GeTXvSuVbcez8R6HOG1Tw_F3A-WETahQdTV38_uc/edit?usp=sharing)
Do the following steps after you download the dataset before you proceed and train your models.
- run preprocess/process.sh (renames images)
- run preprocess/text_file_gen.py (generates txt files for train,val,test used in data generator)
- run preprocess/aug_gen.py (generates augmented image files beforehand the training, dynamic augmentation in runtime is slow an often hangs the training process)
The Following list describes the files :
Improved Architecture with Augmentation & Dropout
- late_fusion_improveed.py (late_fusion FCN TRAINING FILE, Augmentation= Yes, Dropout= Yes)
- late_fusion_improved_predict.py (predict with improved architecture)
- late_fusion_improved_saved_model.hdf5 (Architecture & weights of improved model)
Old Architecture without Augmentation & Dropout
- late_fusion_old.py (late_fusion FCN TRAINING FILE, Augmentation= No, Dropout= No)
- late_fusion_old_predict.py() (predict with old architecture)
- late_fusion_improved_saved_model.hdf5 (Architecture & weights of old model)
Architecture:
 Architecture Reference (first two models in this link): http://deepscene.cs.uni-freiburg.de/index.html
Architecture Reference (first two models in this link): http://deepscene.cs.uni-freiburg.de/index.html
Dataset:
 Dataset Reference (Freiburg forest multimodal/spectral annotated): http://deepscene.cs.uni-freiburg.de/index.html#datasets
Dataset Reference (Freiburg forest multimodal/spectral annotated): http://deepscene.cs.uni-freiburg.de/index.html#datasets
Note:Since the dataset is too small the training will overfit. To overcome this and train a generalized classifier image augmentation is done.
Images are transformed geometrically with a combination of transsformations and added to the dataset before training.

Training: Loss : Categorical Cross Entropy
Optimizer : Stochastic gradient descent with lr = 0.008, momentum = 0.9, decay=1e-6
Results:

NOTE: This following files in the repository ::
1.Deepscene/nir_rgb_segmentation_arc_1.py :: ("CHANNEL-STACKING MODEL") 2.Deepscene/nir_rgb_segmentation_arc_2.py :: ("LATE-FUSION MODEL") 3.Deepscene/nir_rgb_segmentation_arc_3.py :: ("Convoluted Mixture of Deep Experts (CMoDE) Model")
are the exact replicas of the architectures described in Deepscene website.
-
Day 52 (02/21/2022): Visually Indicated Sound-Generation Intuition
-
Day 53 (02/22/2022): Diverse and Specific Image Captioning Intuition
This contains the code for Generating Diverse and Meaningful Captions: Unsupervised Specificity Optimization for Image Captioning (Lindh et al., 2018) to appear in Artificial Neural Networks and Machine Learning - ICANN 2018.
A detailed description of the work, including test results, can be found in our paper: [publisher version] [author version]
Please consider citing if you use the code:
@inproceedings{lindh_generating_2018,
series = {Lecture {Notes} in {Computer} {Science}},
title = {Generating {Diverse} and {Meaningful} {Captions}},
isbn = {978-3-030-01418-6},
doi = {10.1007/978-3-030-01418-6_18},
language = {en},
booktitle = {Artificial {Neural} {Networks} and {Machine} {Learning} – {ICANN} 2018},
publisher = {Springer International Publishing},
author = {Lindh, Annika and Ross, Robert J. and Mahalunkar, Abhijit and Salton, Giancarlo and Kelleher, John D.},
editor = {Kůrková, Věra and Manolopoulos, Yannis and Hammer, Barbara and Iliadis, Lazaros and Maglogiannis, Ilias},
year = {2018},
keywords = {Computer Vision, Contrastive Learning, Deep Learning, Diversity, Image Captioning, Image Retrieval, Machine Learning, MS COCO, Multimodal Training, Natural Language Generation, Natural Language Processing, Neural Networks, Specificity},
pages = {176--187}
}
The code in this repository builds on the code from the following two repositories:
https://github.com/ruotianluo/ImageCaptioning.pytorch
https://github.com/facebookresearch/SentEval/
A note is included at the top of each file that has been changed from its original state. We make these changes (and our own original files) available under Attribution-NonCommercial 4.0 International where applicable (see LICENSE.txt in the root of this repository).
The code from the two repos listed above retain their original licenses. Please see visit their repositories for further details. The SentEval folder in our repo contains the LICENSE document for SentEval at the time of our fork.
Requirements
Python 2.7 (built with the tk-dev package installed)
PyTorch 0.3.1 and torchvision
h5py 2.7.1
sklearn 0.19.1
scipy 1.0.1
scikit-image (skimage) 0.13.1
ijson
Tensorflow is needed if you want to generate learning curve graphs (recommended!)
Setup for the Image Captioning side
For ImageCaptioning.pytorch (previously known as neuraltalk2.pytorch) you need the pretrained resnet model found here, which should be placed under combined_model/neuraltalk2_pytorch/data/imagenet_weights.
You will also need the cocotalk_label.h5 and cocotalk.json from here and the pretrained Image Captioning model from the topdown directory.
To run the prepro scripts for the Image Captioning model, first download the coco images from link. You should put the train2014/ and val2014/ in the same directory, denoted as $IMAGE_ROOT during preprocessing.
There’s some problems with the official COCO images. See this issue about manually replacing one image in the dataset. You should also run the script under utilities/check_file_types.py that will help you find one or two PNG images that are incorrectly marked as JPG images. I had to manually convert these to JPG files and replace them.
Next, download the preprocessed coco captions from link from Karpathy's homepage. Extract dataset_coco.json from the zip file and copy it in to data/. This file provides preprocessed captions and the train-val-test splits.
Once we have these, we can now invoke the prepro_*.py script, which will read all of this in and create a dataset (two feature folders, a hdf5 label file and a json file):
$ python scripts/prepro_labels.py --input_json data/dataset_coco.json --output_json data/cocotalk.json --output_h5 data/cocotalk
$ python scripts/prepro_feats.py --input_json data/dataset_coco.json --output_dir data/cocotalk --images_root $IMAGE_ROOTSee https://github.com/ruotianluo/ImageCaptioning.pytorch for more info on the scripts if needed.
Setup for the Image Retrieval side
You will need to train a SentEval model according to the instructions here using their pretrained InferSent embedder. IMPORTANT: Because of a change in SentEval, you will need to pull commit c7c7b3a instead of the latest version.
You also need the GloVe embeddings you used for this when you’re training the full combined model.
Setup for the combined model
You will need the official coco-caption evaluation code which you can find here:
https://github.com/tylin/coco-caption
This should go in a folder called coco_caption under src/combined_model/neuraltalk2_pytorch
Run the training
$ cd src/combined_model
$ python SentEval/examples/launch_training.py --id <your_model_id> --checkpoint_path <path_to_save_model> --start_from <directory_pretrained_captioning_model> --learning_rate 0.0000001 --max_epochs 10 --best_model_condition mean_rank --loss_function pairwise_cosine --losses_log_every 10000 --save_checkpoint_every 10000 --batch_size 2 --caption_model topdown --input_json neuraltalk2_pytorch/data/cocotalk.json --input_fc_dir neuraltalk2_pytorch/data/cocotalk_fc --input_att_dir neuraltalk2_pytorch/data/cocotalk_att --input_label_h5 neuraltalk2_pytorch/data/cocotalk_label.h5 --learning_rate_decay_start 0 --senteval_model <your_trained_senteval_model> --language_eval 1 --split valThe --loss_function options used for the models in the paper:
Cos = cosine_similarity
DP = direct_similarity
CCos = pairwise_cosine
CDP = pairwise_similarity
See combined_model/neuraltalk2_pytorch/opts.py for a list of the available parameters.
Run the test
$ cd src/combined_model
$ python SentEval/examples/launch_test.py --id <your_model_id> --checkpoint_path <path_to_model> --start_from <path_to_model> --load_best_model 1 --loss_function pairwise_cosine --batch_size 2 --caption_model topdown --input_json neuraltalk2_pytorch/data/cocotalk.json --input_fc_dir neuraltalk2_pytorch/data/cocotalk_fc --input_att_dir neuraltalk2_pytorch/data/cocotalk_att --input_label_h5 neuraltalk2_pytorch/data/cocotalk_label.h5 --learning_rate_decay_start 0 --senteval_model <your_trained_senteval_model> --language_eval 1 --split testTo test the baseline or the latest version of a model (instead of the one marked with 'best' in the name) use:
--load_best_model 0
The --loss_function option will only decide which internal loss function to report the result for. No extra training will be carried out, and the other results won't be affected by this choice.
-
Day 54 (02/23/2022): Brain Activity Classification and Regressive Analysis
-
Day 55 (02/24/2022): Singular Value Decomposition applications in Image Processing
-
Day 56 (02/25/2022): Knowledge Distillation Introduction
knowledge-distillation-pytorch
- Exploring knowledge distillation of DNNs for efficient hardware solutions
- Author Credits: Haitong Li
- Dataset: CIFAR-10
Features
- A framework for exploring "shallow" and "deep" knowledge distillation (KD) experiments
- Hyperparameters defined by "params.json" universally (avoiding long argparser commands)
- Hyperparameter searching and result synthesizing (as a table)
- Progress bar, tensorboard support, and checkpoint saving/loading (utils.py)
- Pretrained teacher models available for download
Install
- Install the dependencies (including Pytorch)
pip install -r requirements.txt
Organizatoin:
- ./train.py: main entrance for train/eval with or without KD on CIFAR-10
- ./experiments/: json files for each experiment; dir for hypersearch
- ./model/: teacher and student DNNs, knowledge distillation (KD) loss defination, dataloader
Key notes about usage for your experiments:
- Download the zip file for pretrained teacher model checkpoints from this Box folder
- Simply move the unzipped subfolders into 'knowledge-distillation-pytorch/experiments/' (replacing the existing ones if necessary; follow the default path naming)
- Call train.py to start training 5-layer CNN with ResNet-18's dark knowledge, or training ResNet-18 with state-of-the-art deeper models distilled
- Use search_hyperparams.py for hypersearch
- Hyperparameters are defined in params.json files universally. Refer to the header of search_hyperparams.py for details
Train (dataset: CIFAR-10)
Note: all the hyperparameters can be found and modified in 'params.json' under 'model_dir'
-- Train a 5-layer CNN with knowledge distilled from a pre-trained ResNet-18 model
python train.py --model_dir experiments/cnn_distill
-- Train a ResNet-18 model with knowledge distilled from a pre-trained ResNext-29 teacher
python train.py --model_dir experiments/resnet18_distill/resnext_teacher
-- Hyperparameter search for a specified experiment ('parent_dir/params.json')
python search_hyperparams.py --parent_dir experiments/cnn_distill_alpha_temp
--Synthesize results of the recent hypersearch experiments
python synthesize_results.py --parent_dir experiments/cnn_distill_alpha_temp
Results: "Shallow" and "Deep" Distillation
Quick takeaways (more details to be added):
- Knowledge distillation provides regularization for both shallow DNNs and state-of-the-art DNNs
- Having unlabeled or partial dataset can benefit from dark knowledge of teacher models
-Knowledge distillation from ResNet-18 to 5-layer CNN
| Model | Dropout = 0.5 | No Dropout |
|---|---|---|
| 5-layer CNN | 83.51% | 84.74% |
| 5-layer CNN w/ ResNet18 | 84.49% | 85.69% |
-Knowledge distillation from deeper models to ResNet-18
| Model | Test Accuracy |
|---|---|
| Baseline ResNet-18 | 94.175% |
| + KD WideResNet-28-10 | 94.333% |
| + KD PreResNet-110 | 94.531% |
| + KD DenseNet-100 | 94.729% |
| + KD ResNext-29-8 | 94.788% |
References
H. Li, "Exploring knowledge distillation of Deep neural nets for efficient hardware solutions," CS230 Report, 2018
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., & Bengio, Y. (2014). Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550.
https://github.com/cs230-stanford/cs230-stanford.github.io
https://github.com/bearpaw/pytorch-classification
-
Day 57 (02/26/2022): 3D Morphable Face Models Intuition They are using Mobilenet to regress sparse 3D Morphable face models (by default (by using only 40 best shape parameters, 10 best shape base parameters (using PCA), 12 parameters for rotational and translation in the equation)) (that seem like landmarks) and then these are then optimized using 2 cost functions (the WPDC and VDC) through an adaptive k-step lookahead (which is the meta-joint optimization). Here, we can see the differences between different Morphable Face Models.
-
Day 58 (02/27/2022): Federated Learning in Pytorch
Implementation of the vanilla federated learning paper : Communication-Efficient Learning of Deep Networks from Decentralized Data. Reference github respository here.
Experiments are produced on MNIST, Fashion MNIST and CIFAR10 (both IID and non-IID). In case of non-IID, the data amongst the users can be split equally or unequally.
Since the purpose of these experiments are to illustrate the effectiveness of the federated learning paradigm, only simple models such as MLP and CNN are used.
Requirments Install all the packages from requirments.txt
pip install -r requirements.txt
Data
- Download train and test datasets manually or they will be automatically downloaded from torchvision datasets.
- Experiments are run on Mnist, Fashion Mnist and Cifar.
- To use your own dataset: Move your dataset to data directory and write a wrapper on pytorch dataset class.
Results on MNIST Baseline Experiment: The experiment involves training a single model in the conventional way.
Parameters:
Optimizer:: SGDLearning Rate:0.01
Table 1: Test accuracy after training for 10 epochs:
| Model | Test Acc |
|---|---|
| MLP | 92.71% |
| CNN | 98.42% |
Federated Experiment: The experiment involves training a global model in the federated setting. Federated parameters (default values):
Fraction of users (C): 0.1Local Batch size (B): 10Local Epochs (E): 10Optimizer: SGDLearning Rate: 0.01
Table 2:Test accuracy after training for 10 global epochs with: | Model | IID | Non-IID (equal)| | ----- | ----- |---- | | MLP | 88.38% | 73.49% | | CNN | 97.28% | 75.94% | Further Readings Find the papers and reading that I had done for understanding this topic more in depth here.
- Day 59 (02/28/2022): Removing Features from Images
- Day 60 (03/01/2022): Slot Filling, Named Entity Recognition, Intent Detection: An Intuition and Review
- Day 61 (03/02/2022): Super Resolution in Remote Sensing I worked at a Remote Sensing company and one of my proposed idea over there was to utilize Deep Learning for saving on the budget. This was because it gets very expensive to purchase High Resolution Imagery from the satellite companies. So, I proposed to utilize Super Resolution based Deep Learning for increasing the Resolution from Low Resolution Imagery. Here, I am going to implement a repository for the same and have the visualization for the same in a Graphical Interchange Format.
- Day 62 (03/03/2022): Deep Dreaming in Computer Vision
- Day 63 (03/04/2022): View Synthesis using Computer Vision
| Novel View Synthesis | Scene Editting + No NVS + GT Depth |
|---|---|
 |
 |
 |
 |
- Day 64 (03/05/2022): Deep Reinforcement Learning in Atari Games












Reinforcement Learning on Atari Games and Control Entrance of program:
- Breakout.py
(1). Check DDQN_params.json, make sure that every parameter is set right.
GAME_NAME # Set the game's name . This will help you create a new dir to save your result.
MODEL_NAME # Set the algorithms and model you are using. This is only used for rename your result file, so you still need
to change the model isntanace manually.
MAX_ITERATION # In original paper, this is set to 25,000,000. But here we set it to 5,000,000 for Breakout.(2,500,000 for Pong will suffice.)
num_episodes # Max number of episodes. We set it to a huge number in default so normally this stop condition
usually won't be satisfied.
# the program will stop when one of the above condition is met.(2). Select the model and game environment instance manually. Currently, we are mainly focusing on DQN_CNN_2015 and Dueling_DQN_2016_Modified.
(3). Run and prey :)
NOTE: When the program is running, wait for a couple of minutes and take a look at the estimated time printed in the
console. Stop early and decrease the MAX_ITERATION if you cannot wait for such a long time. (Recommendation: typically,
24h could be a reasonable running time for your first training process. Since you can continue training your model, take
a rest for both you and computer and check the saved figures to see if your model has a promising future. Hope so ~ )
The breakout.py will automatically save the mid point state and variables for you if the program exit w/o exception.
-
set the middle_point_json file path.
-
check DDQN_params.json, make sure that every parameter is set right. Typically, you need to set a new
MAX_ITERATIONornum_episodes. -
Run and prey :)
evaluation.py helps you evaluate the model. First, please modified param_json_fname and model_list_fname to your
directory. Second, change the game environment instance and the model instance. Then run.
The program will automatically create the the directory like this:
├── GIF_Reuslts
│ └── ModelName:2015_CNN_DQN-GameName:Breakout-Time:03-28-2020-18-20-28
│ ├── Iterations:100000-Reward:0.69-Time:03-28-2020-18-20-27-EvalReward:0.0.gif
│ ├── Iterations:200000-Reward:0.69-Time:03-28-2020-18-20-27-EvalReward:1.0.gif
├── Results
│ ├── ModelName:2015_CNN_DQN-GameName:Breakout-Time:03-28-2020-18-20-28-Eval.pkl
│ └── ModelName:2015_CNN_DQN-GameName:Breakout-Time:03-28-2020-18-20-28.pkl
├── DDQN_params.json
Please zip these three files/folders and upload it to our shared google drive. Rename it, e.g. ModelName:2015_CNN_DQN-GameName:Breakout-Time:03-28-2020-18-20-28.
PS:
GIF_Reuslts record the game process
Results contains the history of training and eval process, which can be used to visualize later.
DDQN_params.json contains your algorithm settings, which should match your Results and GIF_Reuslts.
-
Day 65 (03/06/2022): Molecular Chemistry using Machine Learning
-
Day 66 (03/07/2022): Face Frontalization
-
Day 67 (03/08/2022): ECCV2020 Papers and Implementations
-
Day 68 (03/09/2022): Textured 3D generative Adversarial Networks
-
Day 69 (03/10/2022): Hyperbolic Learning
Referred from: Drew Wilimitis
It has been recently established that many real-world networks have a latent geometric structure that resembles negatively curved hyperbolic spaces. Therefore, complex networks, and particularly the hierarchical relationships often found within, can often be more accurately represented by embedding graphs in hyperbolic geometry, rather than flat Euclidean space.
The goal of this project is to provide Python implementations for a few recently published algorithms that leverage hyperbolic geometry for machine learning and network analysis. Several examples are given with real-world datasets, however; the time complexity is far from optimized and this repository is primarily for research purposes - specifically investigating how to integrate downstream supervised learning methods with hyperbolic embeddings.

-
Poincaré Embeddings:
- Mostly an exploration of the hyperbolic embedding approach used in [1].
- Available implementation in the
gensimlibrary and a PyTorch version released by the authors here.
-
Hyperbolic Multidimensional Scaling: nbviewer
- Finds embedding in Poincaré disk with hyperbolic distances that preserve input dissimilarities [2].
-
K-Means Clustering in the Hyperboloid Model: nbviewer
- Optimization approach using Frechet means to define a centroid/center of mass in hyperbolic space [3, 4].
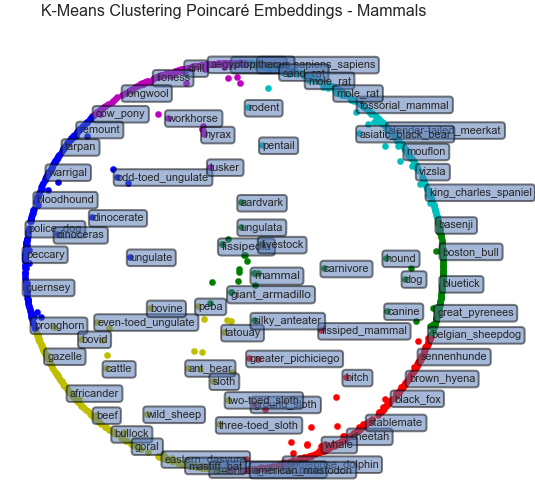
-
Hyperbolic Support Vector Machine - nbviewer
- Linear hyperbolic SVC based on the max-margin optimization problem in hyperbolic geometry [5].
- Uses projected gradient descent to define decision boundary and predict classifications.
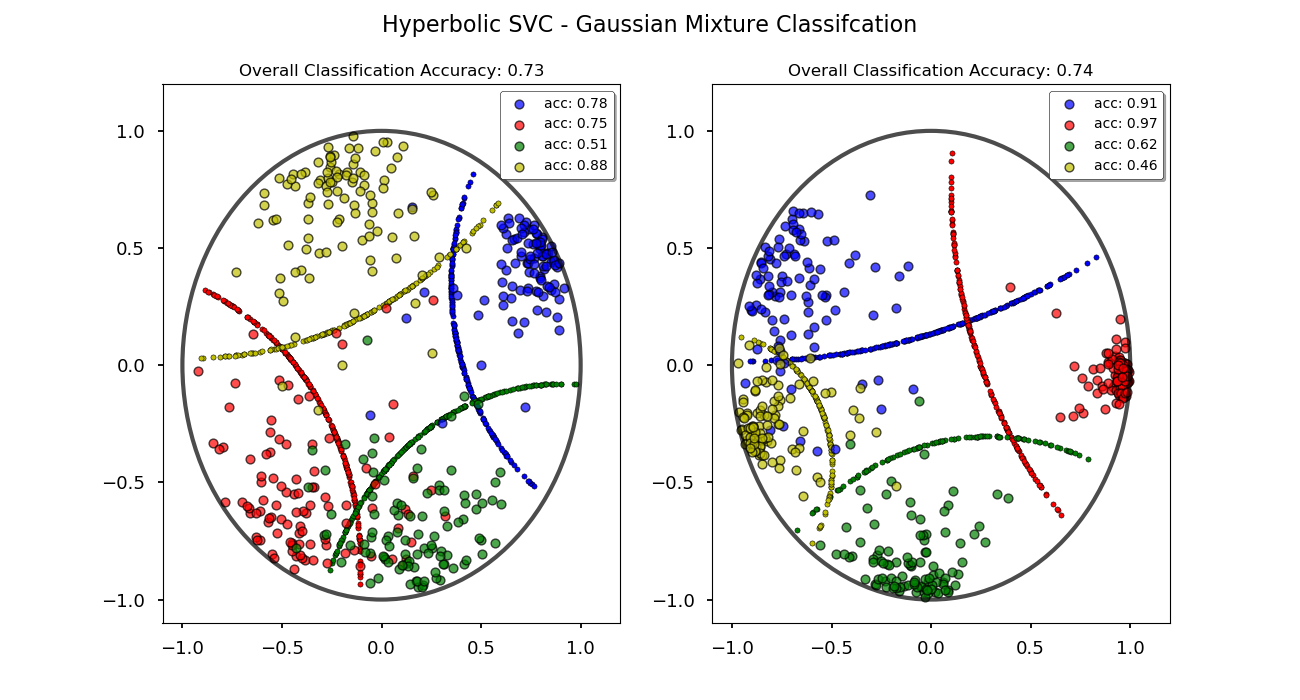
-
Hyperbolic Gaussian Mixture Models - nbviewer
- Iterative Expectation-Maximization (EM) algorithm used for clustering [6].
- Wrapped normal distribution based on using parallel transport to map to hyperboloid
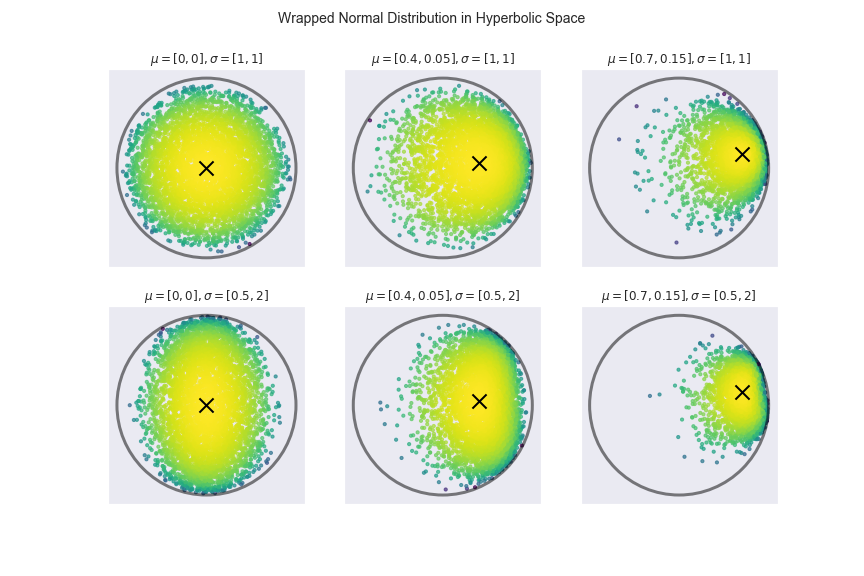
-
Embedding Graphs in Lorentzian Spacetime - nbviewer
- An algorithm based on notions of causality in the Minkowski spacetime formulation of special relativity [7].
- Used to embed directed acyclic graphs where nodes are represented by space-like and time-like coordinates.
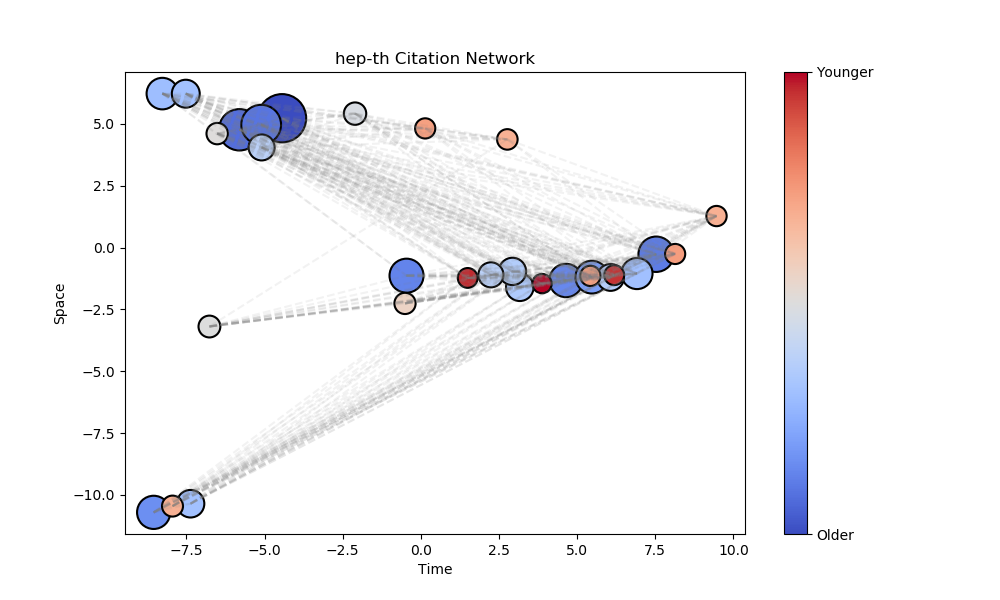
-
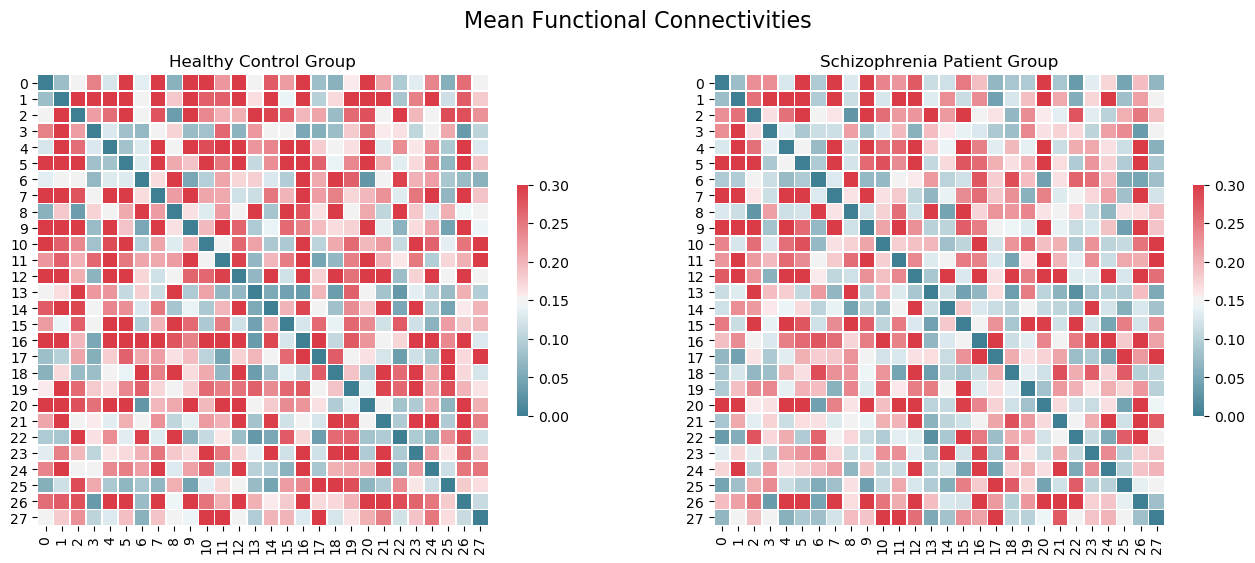
Application: fMRI Schizophrenia Classification - nbviewer
- Deriving hyperbolic features from functional network connectomes and predicting schizophrenia.
- Analyzing discriminating factors from coalescent embeddings and hyperbolic kmeans clustering
- Zachary Karate Club Network
- WordNet
- Enron Email Corpus
- Polbooks Network
- arXiv Citation Network
- Synthetic generated data (sklearn.make_datasets, networkx.generators, etc.)
- Models are designed based on the sklearn estimator API (
sklearngenerally used only in rare, non-essential cases) Networkxis used to generate & display graphs
[1] Nickel, Kiela. "Poincaré embeddings for learning hierarchical representations" (2017). arXiv.
[2] A. Cvetkovski and M. Crovella. Multidimensional scaling in the Poincaré disk. arXiv:1105.5332, 2011.
[3] "Learning graph-structured data using Poincaré embeddings and Riemannian K-means algorithms". Hatem Hajri, Hadi Zaatiti, Georges Hebrail (2019) arXiv.
[4] Wilson, Benjamin R. and Matthias Leimeister. “Gradient descent in hyperbolic space.” (2018).
[5] "Large-margin classification in hyperbolic space". Cho, H., Demeo, B., Peng, J., Berger, B. CoRR abs/1806.00437 (2018).
[6] Nagano, Yoshihiro et al. “A Differentiable Gaussian-like Distribution on Hyperbolic Space for Gradient-Based Learning.” ArXiv abs/1902.02992 (2019)
[7] Clough JR, Evans TS (2017) Embedding graphs in Lorentzian spacetime. PLoS ONE 12(11):e0187301. https://doi.org/10.1371/journal.pone.0187301.
- Day 70 (03/11/2022): Critically-damped Langevin Diffusion

Requirements
CLD-SGM is built in Python 3.8.0 using PyTorch 1.8.1 and CUDA 11.1. Please use the following command to install the requirements:
pip install --upgrade pip
pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.html -f https://storage.googleapis.com/jax-releases/jax_releases.htmlOptionally, you may also install NVIDIA Apex. The Adam optimizer from this library is faster than PyTorch's native Adam.
Preparations
CIFAR-10 does not require any data preparation as the data will be downloaded directly. To download CelebA-HQ-256 and prepare the dataset for training models, please run the following lines:
mkdir -p data/celeba/
wget -P data/celeba/ https://openaipublic.azureedge.net/glow-demo/data/celeba-tfr.tar
tar -xvf data/celeba/celeba-tfr.tar -C data/celeba/
python util/convert_tfrecord_to_lmdb.py --dataset=celeba --tfr_path=data/celeba/celeba-tfr --lmdb_path=data/celeba/celeba-lmdb --split=train
python util/convert_tfrecord_to_lmdb.py --dataset=celeba --tfr_path=data/celeba/celeba-tfr --lmdb_path=data/celeba/celeba-lmdb --split=validationFor multi-node training, the following environment variables need to be specified: $IP_ADDR is the IP address of the machine that will host the process with rank 0 during training (see here). $NODE_RANK is the index of each node among all the nodes.
Checkpoints
We provide pre-trained CLD-SGM checkpoints for CIFAR-10 and CelebA-HQ-256 here.
Training and evaluation
CIFAR-10
- Training our CIFAR-10 model on a single node with one GPU and batch size 64:
python main.py -cc configs/default_cifar10.txt -sc configs/specific_cifar10.txt --root $ROOT --mode train --workdir work_dir/cifar10 --n_gpus_per_node 1 --training_batch_size 64 --testing_batch_size 64 --sampling_batch_size 64Hidden flags can be found in the config files: configs/default_cifar10.txt and configs/specific_cifar10.txt. The flag --sampling_batch_size indicates the batch size per GPU, whereas --training_batch_size and --eval_batch_size indicate the total batch size of all GPUs combined. The script will update a running checkpoint every --snapshot_freq iterations (saved, in this case, at work_dir/cifar10/checkpoints/checkpoint.pth), starting from --snapshot_threshold. In configs/specific_cifar10.txt, these values are set to 10000 and 1, respectively.
- Training our CIFAR-10 model on two nodes with 8 GPUs each and batch size 128:
mpirun --allow-run-as-root -np 2 -npernode 1 bash -c 'python main.py -cc configs/default_cifar10.txt -sc configs/specific_cifar10.txt --root $ROOT --mode train --workdir work_dir/cifar10 --n_gpus_per_node 8 --training_batch_size 8 --testing_batch_size 8 --sampling_batch_size 128 --node_rank $NODE_RANK --n_nodes 2 --master_address $IP_ADDR'- To resume training, we simply change the mode from train to continue (two nodes of 8 GPUs):
mpirun --allow-run-as-root -np 2 -npernode 1 bash -c 'python main.py -cc configs/default_cifar10.txt -sc configs/specific_cifar10.txt --root $ROOT --mode continue --workdir work_dir/cifar10 --n_gpus_per_node 8 --training_batch_size 8 --testing_batch_size 8 --sampling_batch_size 128 --cont_nbr 1 --node_rank $NODE_RANK --n_nodes 2 --master_address $IP_ADDR'Any file within work_dir/cifar10/checkpoints/ can be used to resume training by setting --checkpoint to the particular file name. If --checkpoint is unspecified, the script automatically uses the last snapshot checkpoint (checkpoint.pth) to continue training. The flag --cont_nbr makes sure that a new random seed is used for training continuation; for additional continuation runs --cont_nbr may be incremented by one.
- The following command can be used to evaluate the negative ELBO as well as the FID score (two nodes of 8 GPUs):
mpirun --allow-run-as-root -np 2 -npernode 1 bash -c 'python main.py -cc configs/default_cifar10.txt -sc configs/specific_cifar10.txt --root $ROOT --mode eval --workdir work_dir/cifar10 --n_gpus_per_node 8 --training_batch_size 8 --testing_batch_size 8 --sampling_batch_size 128 --eval_folder eval_elbo_and_fid --ckpt_file checkpoint_file --eval_likelihood --eval_fid --node_rank $NODE_RANK --n_nodes 2 --master_address $IP_ADDR'Before running this you need to download the FID stats file from here and place it into $ROOT/assets/stats/).
To evaluate our provided CIFAR-10 model download the checkpoint here, create a directory work_dir/cifar10_pretrained_seed_0/checkpoints, place the checkpoint in it, and set --ckpt_file checkpoint_800000.pth as well as --workdir cifar10_pretrained.
CelebA-HQ-256
- Training the CelebA-HQ-256 model from our paper (two nodes of 8 GPUs and batch size 64):
mpirun --allow-run-as-root -np 2 -npernode 1 bash -c 'python main.py -cc configs/default_celeba_paper.txt -sc configs/specific_celeba_paper.txt --root $ROOT --mode train --workdir work_dir/celeba_paper --n_gpus_per_node 8 --training_batch_size 4 --testing_batch_size 4 --sampling_batch_size 64 --data_location data/celeba/celeba-lmdb/ --node_rank $NODE_RANK --n_nodes 2 --master_address $IP_ADDR'We found that training of the above model can potentially be unstable. Some modifications that we found post-publication lead to better numerical stability as well as improved performance:
mpirun --allow-run-as-root -np 2 -npernode 1 bash -c 'python main.py -cc configs/default_celeba_post_paper.txt -sc configs/specific_celeba_post_paper.txt --root $ROOT --mode train --workdir work_dir/celeba_post_paper --n_gpus_per_node 8 --training_batch_size 4 --testing_batch_size 4 --sampling_batch_size 64 --data_location data/celeba/celeba-lmdb/ --node_rank $NODE_RANK --n_nodes 2 --master_address $IP_ADDR'In contrast to the model reported in our paper, we make use of a non-constant time reparameterization function β(t). For more details, please check the config files.
Toy data
- Training on the multimodal Swiss Roll dataset using a single node with one GPU and batch size 512:
python main.py -cc configs/default_toy_data.txt --root $ROOT --mode train --workdir work_dir/multi_swiss_roll --n_gpus_per_node 1 --training_batch_size 512 --testing_batch_size 512 --sampling_batch_size 512 --dataset multimodal_swissrollAdditional toy datasets can be implemented in util/toy_data.py.
Monitoring the training process
We use Tensorboard to monitor the progress of training. For example, monitoring the CIFAR-10 process can be done as follows:
tensorboard --logdir work_dir/cifar10_seed_0/tensorboardDemonstration
Load our pretrained checkpoints and play with sampling and likelihood computation:
| Link | Description |
|---|---|
| CIFAR-10 | |
| CelebA-HQ-256 |
Citation If you find the code useful for your research, please consider citing our ICLR paper:
@inproceedings{dockhorn2022score,
title={Score-Based Generative Modeling with Critically-Damped Langevin Diffusion},
author={Tim Dockhorn and Arash Vahdat and Karsten Kreis},
booktitle={International Conference on Learning Representations (ICLR)},
year={2022}
}-
Day 71 (03/12/2022): Vector Quantized Variational AutoEncoders
-
Day 72 (03/13/2022): Revisiting Basic Machine Learning
-
Day 73 (03/14/2022): SemanticStyleGAN
-
Day 74 (03/15/2022): Cross Lingual Language Models (XLM) and Meta Agnostic Meta-Learning (MAML)
-
Day 75 (03/16/2022): µTransfer HP Tuning of Enormous Neural Nets
-
Day 76 (03/17/2022): Data Augmentation in Natural Language Processing
-
Day 77 (03/18/2022): Introduction to MediaPipe
-
Day 78 (03/19/2022): Manifold Learning
-
Day 79 (03/20/2022): SPD fMRI
-
Day 80 (03/21/2022): MPS-Net: 3D Human PoseShape from Videos
-
Day 81 (03/22/2022): Mask Transfiner High Quality Instance Segmentation
-
Day 82 (03/23/2022): Generating Informative Drawings
-
Day 83 (03/24/2022): WISE-FT: Robust Fine-tuning of Zero-Shot Models
-
Day 84 (03/25/2022): Explainable AI in GANs
-
Day 85 (03/26/2022): Deep Image Matting
-
Day 86 (03/27/2022): HybridNets
-
Day 87 (03/28/2022): Introduction to Data Mining and Knowledge Graphs
-
Day 88 (03/29/2022): GFlowNet: An Intuition and Implementation
-
Day 89 (03/30/2022): Neural Rendering: An Intuition
-
Day 90 (03/31/2022): Scene Representation Networks
-
Day 91 (04/01/2022): Generative Query Network
-
Day 92 (04/02/2022): Neural Volumes
-
Day 93 (04/03/2022): Modelling Deformable Geometries with CaDeX
-
Day 94 (04/04/2022): Neural Rendering using Neural Radiance Fields: An Intuition
-
Day 95 (04/05/2022): Differential Surface Splatting
DSS: Differentiable Surface Splatting
| Paper PDF | Project page |
|---|

code for paper Differentiable Surface Splatting for Point-based Geometry Processing
+ Mar 2021: major updates tag 2.0.
+ > Now supports simultaneous normal and point position updates.
+ > Unified learning rate using Adam optimizer.
+ > Highly optimized cuda operations
+ > Shares pytorch3d structure- install prequisitories. Our code uses python3.8, pytorch 1.6.1, pytorch3d. the installation instruction requires the latest anaconda.
# install cuda, cudnn, nccl from nvidia
# we tested with cuda 10.2 and pytorch 1.6.0
# update conda
conda update -n base -c defaults conda
# install requirements
conda create -n pytorch3d python=3.8
conda config --add channels pytorch
conda config --add channels conda-forge
conda activate pytorch3d
conda install -c pytorch pytorch=1.6.0 torchvision cudatoolkit=10.2
conda install -c conda-forge -c fvcore -c iopath fvcore iopath
conda install -c bottler nvidiacub
conda install pytorch3d -c pytorch3d
conda install --file requirements.txt
pip install "git+https://github.com/mmolero/pypoisson.git"- clone and compile
git clone --recursive https://github.com/yifita/DSS.git
cd dss
# compile external dependencies
cd external/prefix
python setup.py install
cd ../FRNN
python setup.py install
cd ../torch-batch-svd
python setup.py install
# compile library
cd ../..
python setup.py develop**Demos inverse rendering - shape deformation
# create mvr images using intrinsics defined in the script
python scripts/create_mvr_data_from_mesh.py --points example_data/mesh/yoga6.ply --output example_data/images --num_cameras 128 --image-size 512 --tri_color_light --point_lights --has_specular
python train_mvr.py --config configs/dss.ymlCheck the optimization process in tensorboard.
tensorboard --logdir=exp/dss_proj

video

cite Please cite us if you find the code useful!
@article{Yifan:DSS:2019,
author = {Yifan, Wang and
Serena, Felice and
Wu, Shihao and
{\"{O}}ztireli, Cengiz and
Sorkine{-}Hornung, Olga},
title = {Differentiable Surface Splatting for Point-based Geometry Processing},
journal = {ACM Transactions on Graphics (proceedings of ACM SIGGRAPH ASIA)},
volume = {38},
number = {6},
year = {2019},
}
We would like to thank Federico Danieli for the insightful discussion, Phillipp Herholz for the timely feedack, Romann Weber for the video voice-over and Derek Liu for the help during the rebuttal. This work was supported in part by gifts from Adobe, Facebook and Snap, Inc.
-
Day 96 (04/06/2022): TansPose Intuition
-
Day 97 (04/07/2022): Transformers: A Comprehensive Intuition
-
Day 98 (04/08/2022): Human Activity Recognition
-
Day 99 (04/09/2022): LiDAR and 3D Computer Vision
-
Day 100 (04/10/2022):