Handwritten Text Recognition
For a full description, see the project report: https://github.com/alarxx/HTR/blob/main/report.ipynb
- CMNIST: https://github.com/bolattleubayev/cmnist
- KOHTD: Kazakh Offline Handwritten Text Dataset: https://github.com/abdoelsayed2016/KOHTD
Handwriting recognition can mean 2 things:
On-line: recognizing handwriting when written on the tablet screen directly, which is considered a simpler task
- pen-based computer screen surface
- pen-up and pen-down switching
- pen pressure
- velocity/changes of writing direction
- specifically
Off-line: recognizing handwriting from photos (our aim)
- piece of paper
- image
For Handwriting Recognition (HWR):
- Optical Character Recognition (OCR)
- Intelligent character recognition (ICR)
- Intelligent Word Recognition (IWR)
OCR engines are primarily focused on character-by-character machine printed text recognition from a scanned document and ICR for different fonts or even handwritten text:
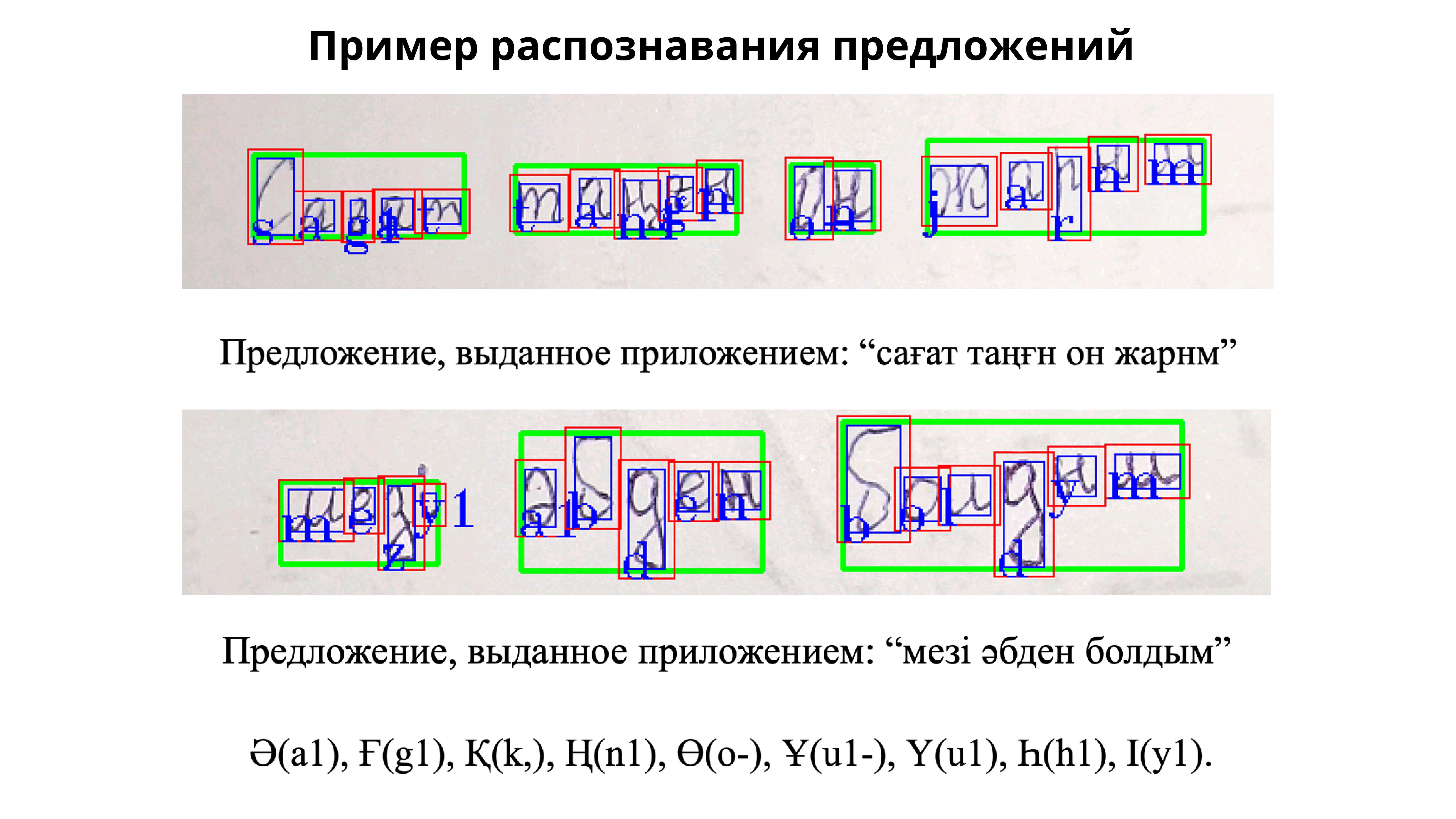
Intelligent Word Recognition (IWR) is the recognition of unconstrained handwritten words. IWR recognizes entire handwritten words or phrases instead of character-by-character, like its predecessors. (our aim).


General Algorithm of the applied Text Detection
- Estimation of average text height using EAST
- Morphological transformation finds text regions.
- Visualization and cropping out text regions for further analysis.
Morphological kernel is necessary to identify lines of text. Its width is proportional to the height of the text and also conventionally kernel size must be an odd number.
The approach combines the advantages of deep model (EAST) with classical image processing methods.

Limitations
The method is designed to detect individual words on white paper, where the lines of text are written horizontally. This is a limitation, because handwritten text can be written in different structures, in a circle, in tables, and there can be different mathematical formulas and these requires a different research.
- Alphabet Recognition to prove that model can classify letters on CMNIST
- Word Recognition with CTC Loss on KOHTD
Подход с распознаванием слов (IWR) с CTC Loss можно назвать end-to-end решением распознавания слов, так как он не включает промежуточного поиска букв, как это делается в OCR или ICR. Но, несмотря на это сама модель распознавания остается без кардинальных изменений, поэтому для доказательства, что модель способна распознавать отдельные буквы, мы сперва экспериментируем с распознаванием алфавита. End-to-end подход подразумевает, что модель будет последовательно распознавать участки изображения, двигаясь слева направо, для каждого участка выдавая вектор вероятностей каждой буквы алфавита, а также вероятность промежуточного межбуквенного пространства (blank). Легче описать это так, будто мы скармливаем модели области изображения, но на самом деле такой подход не был бы оптимальным и в реализации мы делаем не так. CNN могут обрабатывать изображения почти любой размерности, проблема будет только с конечным MLP, который принимает вектор определенной размерности, для решения этого существуют так называемые Fully CNN, которые принимают изображения любой размерности и выдают варьирующуюся размерность. Это важно знать, так как при распознавании слов, наша модель принимает изображения слова целиком и выдает матрицу с варьирующимся количеством столбцов, где каждый столбец это вектор вероятностей буквы или blank-а на участке изображения, в нашей реализации участка размером rx8. Эта варьирующаяся длина достигается за счет Global Max Pooling-а (GMP) по высоте. В нашей реализации модели для каждой области rx8 после GMP у нас вектор размерностью 512, который мы подаем на MLP, а количество таких векторов зависит от ширины подаваемого на вход изображения, что должно быть равно width // 8.
VGG-like модель с Global Max Pooling-ом по высоте и после MLP. Это CNN, которая, принимает изображения почти любой размерности и выдает характеристики, как будто временной ряд, который потенциально мы дальше можем передать на соответствующие модели, которые обрабатывают временные ряды типа LSTM, GRU или Transformer.
Для классификации букв используется GMP выдающий 1x1.
Количество и сверточных и пулинговых слоев расчитано исходя из Receptive Field-а так, чтобы модель могла распознавать паттерны 64x64.
VGG (Simonyan & Zisserman, 2014).
GAP (Lin, 2013).

The project is deployed on Google Cloud using a student subscription plan. We built the backend using Django framework, while the frontend was developed with basic HTML, CSS, and JavaScript without any additional frameworks. The system uses SQLite as a database to store information about previously processed images, which helps avoid analyzing the same image multiple times. Our file structure includes two main folders - 'uploads' for storing original images and 'processed' for keeping the analyzed versions. When a user uploads an image, the system first checks if it exists in SQLite, and if found, returns the cached result instead of running the analysis again. The backend runs on Gunicorn without containerization, which handles all the server operations. This setup provides a functional system for image processing while maintaining good performance through caching.
Alphabet Recognition:
Achieved a validation F1-Score of 96.33% and test accuracy of 96.38%. These results validate the model’s ability to classify individual characters effectively.
Word Recognition:
Achieved a Character Error Rate (CER) of 3.66% and Word Error Rate (WER) of 22.71% on the test dataset. We obtained results on par with the best results of the dataset authors KOHTD: best CER 6.52%, best WER 22.60% (Toiganbayeva et al., 2022). Since this is Error Rate, the lower the value, the better. But, it's important to clarify that we only classified letters of the alphabet.
- Circular text recognition
- Table detection and structure recognition
- Sequential patterns of texts for recognition or post-processing
- End-to-end model for text detection and recognition
- Speech Recognition
- Issue Tracker:
- Source Code: https://github.com/alarxx/HTR/
Let us know if you have issues. Contact: alar.akilbekov@gmail.com
This file is part of the HTR Project – a demo pipeline for Intelligent Word Recognition of unconstrained handwritten text.
Copyright © 2024 Alar Akilbekov, Baktiyar Toksanbay
All Rights Reserved.
SPDX-License-Identifier: MPL-2.0
--------------------------------
This Source Code Form is subject to the terms of the Mozilla Public License, v. 2.0. If a copy of the MPL was not distributed with this file, You can obtain one at https://mozilla.org/MPL/2.0/.
Contact: alar.akilbekov@gmail.com
Fundamental Books:
- Bishop, C. M., & Nasrabadi, N. M. (2006). Pattern recognition and machine learning (Vol. 4, No. 4, p. 738). New York: springer.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. The MIT press.
- Raschka, S., Liu, Y., Mirjalili, V., & Dzhulgakov, D. (2022). Machine learning with PyTorch and Scikit-Learn: Develop machine learning and deep learning models with Python. Packt.
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. (2023). Dive into deep learning. Cambridge University Press.
Beginner level books:
- Rashid, T. (2016). Make Your own neural network. CreateSpace Independent Publishing Platform.
- Weidman, S. (2019). Deep learning from scratch: Building with Python from first principles (First edition). O’Reilly Media, Inc.
- Patterson, J., & Gibson, A. (2017). Deep learning: A practitioner’s approach (First edition). O’Reilly.
OpenCV:
- Kaehler, A., & Bradski, G. (2016). Learning OpenCV 3: computer vision in C++ with the OpenCV library. " O'Reilly Media, Inc.".
- Szeliski, R. (2022). Computer vision: algorithms and applications. Springer Nature.
- Прохоренок, Н. А. (2018). OpenCV и Java. Обработка изображений и компьютерное зрение. БХВ-Петербург.
Text Detection References:
- https://googlecode.blogspot.com/2006/08/announcing-tesseract-ocr.html
- https://sourceforge.net/projects/tesseract-ocr/
- Smith, R. (2007, September). An overview of the Tesseract OCR engine. In Ninth international conference on document analysis and recognition (ICDAR 2007) (Vol. 2, pp. 629-633). IEEE.
- EAST TEXT DETECTION EXAMPLE: https://github.com/opencv/opencv/blob/master/samples/dnn/text_detection.py
- Text detection model: https://github.com/argman/EAST
- Download link: https://www.dropbox.com/s/r2ingd0l3zt8hxs/frozen_east_text_detection.tar.gz?dl=1
- Zhou, X., Yao, C., Wen, H., Wang, Y., Zhou, S., He, W., & Liang, J. (2017). East: an efficient and accurate scene text detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 5551-5560).
- Canny, J. (1986). A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence, (6), 679-698.
- https://docs.opencv.org/4.x/d9/d61/tutorial_py_morphological_ops.html
- Vincent, L. (1991). Morphological transformations of binary images with arbitrary structuring elements. Signal processing, 22(1), 3-23.
Papers:
- Graves, A., Fernández, S., Gomez, F., & Schmidhuber, J. (2006, June). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (pp. 369-376).
- Lin, M. (2013). Network in network. arXiv preprint arXiv:1312.4400.
- Nurseitov, D., Bostanbekov, K., Kurmankhojayev, D., Alimova, A., Abdallah, A., & Tolegenov, R. (2021). Handwritten Kazakh and Russian (HKR) database for text recognition. Multimedia Tools and Applications, 80(21), 33075-33097.
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Toiganbayeva, N., Kasem, M., Abdimanap, G., Bostanbekov, K., Abdallah, A., Alimova, A., & Nurseitov, D. (2022). Kohtd: Kazakh offline handwritten text dataset. Signal Processing: Image Communication, 108, 116827.
YouTube:
- Евгений Разинков. (2023). Machine Learning (2023, spring). https://www.youtube.com/playlist?list=PL6-BrcpR2C5SCyFvs9Xojv24povpBCI6W
- Евгений Разинков. (2022). Лекции по машинному обучению (осень, 2022). https://www.youtube.com/playlist?list=PL6-BrcpR2C5QYSAfoG8mbQUsI9zPVnlBV
- Евгений Разинков. (2021). Лекции по Advanced Computer Vision (2021). https://www.youtube.com/playlist?list=PL6-BrcpR2C5RV6xfpM7_k5321kJrcKEO0
- Евгений Разинков. (2021). Лекции по Deep Learning. https://www.youtube.com/playlist?list=PL6-BrcpR2C5QrLMaIOstSxZp4RfhveDSP
- Евгений Разинков. (2020). Лекции по компьютерному зрению. https://www.youtube.com/playlist?list=PL6-BrcpR2C5RZnmIWs6x0C2IZK6N9Z98I
- Евгений Разинков. (2019). Лекции по машинному обучению. https://www.youtube.com/playlist?list=PL6-BrcpR2C5RYoCAmC8VQp_rxSh0i_6C6