
Designed and developed by Sever Topan
- Feature Abstract (below)
- Installation Instructions
- Tutorial
- Class Documentation
- Examples
- AdjSim DEV Talk
At its core, AdjSim is an agent-based modelling engine. It allows users to define simulation environments through which agents interact through ability casting and timestep iteration. The framework is targeted towards agents that behave intelligently, for example a bacterium chasing down food. However, the framework is extremely flexible - from enabling physics simulation to defining an environment in which Conway's Game of Life plays out! AdjSim aims to be a foundational architecture on top of which reinforcement learning can be built.
The AdjSim architecture differs from frameworks such as OpenAI Gym in that multiple agents can be trained simultaneously within an environment. Thus "hive-mind" complexes can be developed. Additionally, the concept of reward is independent from the environment. An agent can generate its own value system based on its own interpretation of the observations from its environment; observations and rewards are fundamentally decoupled.
The simulation can be viewed in real time as it unfolds, with graphics are rendered and animated using PyQt5. Below are four of the distinct examples packadged with AdjSim, ranging from bacteria to moon system simulation.
 |
 |
|---|---|
 |
 |
Agent properties can be marked for tracking during simulation, allowing for viewing the results of these values once the simulation completes. For example, we can track the population of each different type of agent, or the efficacy of the agent's ability to meet its intelligence module-defined goals.
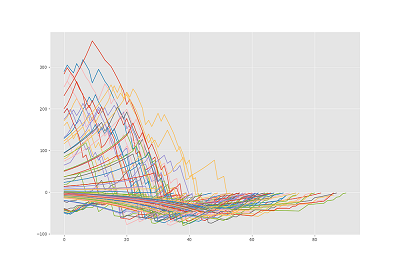 |
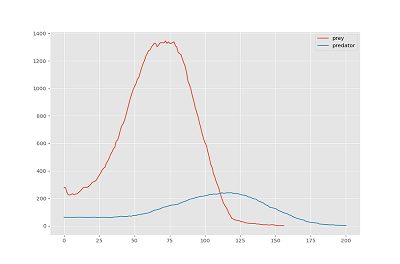 |
|---|
Perhaps the most computationally interesting aspect of AdjSim lies in its intelligence module. It allows agents to set goals (for example, the goal of a bacterium may be to maximize its calories), and assess its actions in terms of its ability to meet its goals. This allows the agents to learn which actions are best used in a given situation. Currently the intelligence module implements Q-Learning, but more advanced reinforcement learning techniques are coming soon!