
PaddleOCR performs the Optical Character Recognition (OCR) function from a video, an image, or a scanned document. It is mainly composed of three parts: DB text detection, detection frame correction and CRNN text recognition. For more details, please refer to the PaddleOCR technical article (https://arxiv.org/abs/2009.09941).
This notebook demonstrates live paddleOCR inference with OpenVINO. We use the "Chinese and English ultra-lightweight PP-OCR model (9.4M)" from PaddleOCR Github or PaddleOCR Gitee. Both text detection and recognition results are visualized in a window, and text recognition results provided include both recognized text and its corresponding confidence level. In the notebook we show how to create the following pipeline:
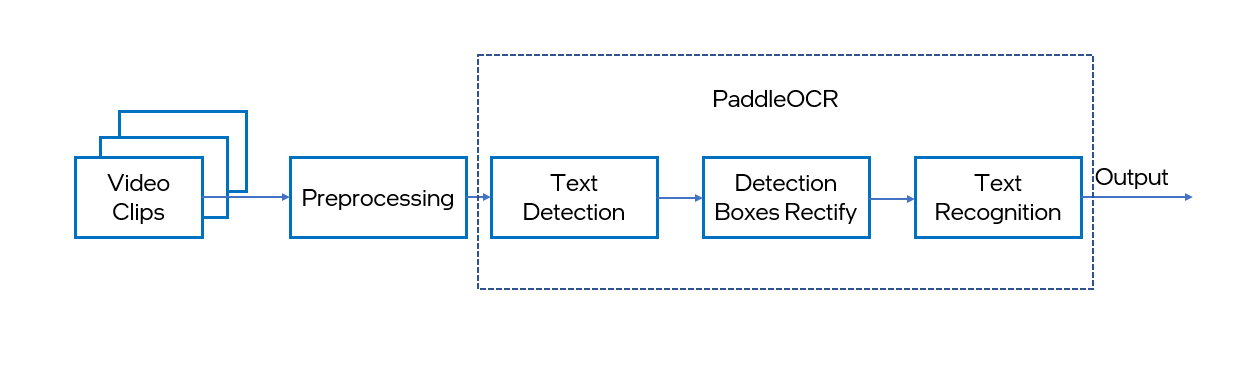
At the end of this notebook, you will see live inference results from your webcam. You can also upload a video file.
NOTE: To use the webcam, you must run this Jupyter notebook on a computer with a webcam. If you run on a server, the webcam will not work. However, you can still do inference on a video in the final step.
For more information about the other PaddleOCR pre-trained models, refer to the PaddleOCR Github or PaddleOCR Gitee.
If you have not done so already, please follow the Installation Guide to install all required dependencies.