Machine learning is making sense of data.

In traditional machine learning, the learning process is supervised and the programmer has to be very, very specific when telling the computer what types of things it should be looking for when deciding if an image contains a dog or does not contain a dog. This is a laborious process called feature extraction and the computer's success rate depends entirely upon the programmer's ability to accurately define a feature set for "dog."
Computer programs that use deep learning go through much the same process. Each algorithm in the hierarchy applies a nonlinear transformation on its input and uses what it learns to create a statistical model as output. Iterations continue until the output has reached an acceptable level of accuracy. The number of processing layers through which data must pass is what inspired the label deep.
Neural networks are universal function optimisers.
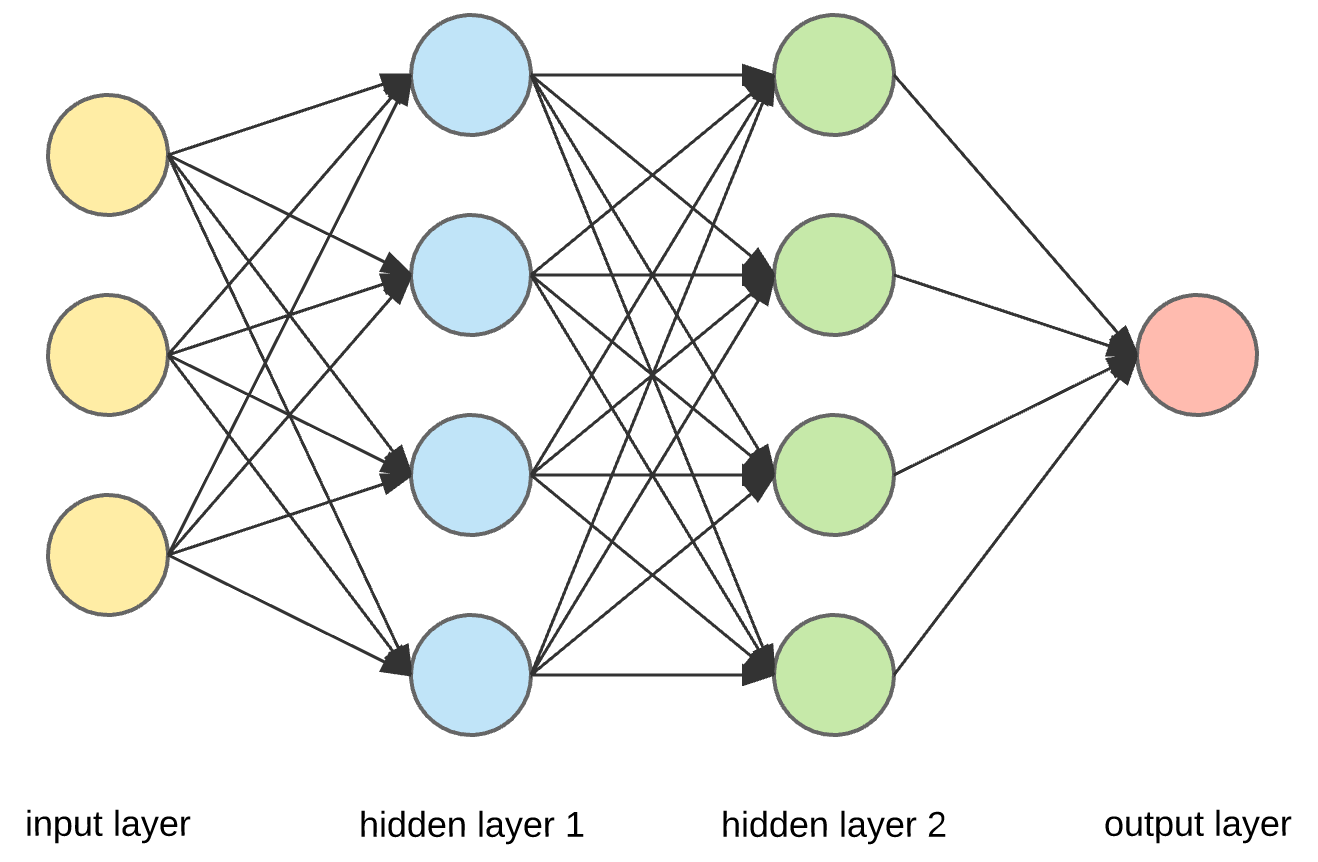

Its a scientific computation package in python which helps to use the power of GPUs and its a deep learning research platform.
Tensors are similar to numpy ndarrays but it can be also be used on GPUs for fast computations.
import torchLets construct an empty matrix
x = torch.empty(5, 3)output..
tensor([[-5.0254e+18, 4.5609e-41, -5.0254e+18],
[ 4.5609e-41, 1.6395e-43, 1.3873e-43],
[ 1.4574e-43, 4.4842e-44, 1.4293e-43],
[ 1.4714e-43, 1.5134e-43, 1.4153e-43],
[ 4.4842e-44, 1.5554e-43, 1.5975e-43]])
other tensor operators are torch.rand(), torch.zeros(), torch.tensor() ..etc.
Addition,
print(torch.add(x, y))Converting a torch tensor to numpy and vice versa is simple in PyTorch.
a = torch.ones(5)
a = a.numpy()In reverse,
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)Autograd is automatic differentiation by calling .backward()
torch.Tensor is the central class of the package. If you set its attribute .requires_grad as True, it starts to track all operations on it. When you finish your computation you can call .backward() and have all the gradients computed automatically.
autograd.Function implements forward and backward definitions of an autograd operation.
- Define the neural network that has some learnable parameters (or weights)
- terate over a dataset of inputs
- Process input through the network
- Compute the loss (how far is the output from being correct)
- Propagate gradients back into the network’s parameters
- Update the weights of the network, typically using a simple update rule:
weight = weight - learning_rate * gradient